

Python systems
Published on May 4, 2024
Last updated on Jan 21, 2025
Abstraction enables opportunity
Complex societies are built on abstraction and supply chains. In no career path is this more evident than software. Developers start the journey at different times, building careers that rely heavily on evolving ladders of abstraction.
The abstractions present at any given time enable available careers like how language enables thought patterns. As technology evolves, new supply chains emerge while old ones stabilize and sometimes go obsolete. Marketable specialized skills shift, usually towards higher-level technologies, but not always. It is easy to miss the OGs that remain maintaining and optimizing the machines that make the machines.

https://xkcd.com/2347/
Undifferentiated activity at low levels becomes infrastructure, a boring place where many promising, thankless projects and opportunities lurk. The jobs aren’t sexy, require specialized knowledge most don’t appreciate and can’t find in a search engine or chat interface; but this form of knowledge drives careers of many of the most successful engineers and researchers I’ve encountered.
This article takes a baby step in applying this frame to the Python programming language, the swiss army knife of modern software and lingua franca of AI devs. Specifically, we’ll look at how Python interfaces with lower-level systems programming languages.
Python is the hot high-level abstraction, seeing its interfaces is an edge
You don’t need to be a full-time infra person to see career benefits from thinking more about what goes on under the hood.
Python’s status as a high-level programming language (read: looks similar to how regular people speak) means it is relatively easy to learn the basics. It was built for programming education, after all. Despite these humble origins, many pro engineers now use Python in critical systems, and for many scenarios it is unacceptable to outsource understanding of the language powering the language.
Ongoing trends in AI commoditize middling levels of knowledge and incentivizes types of knowledge that are critical to bias the context window of a human + AI interaction in the most useful ways:
- special, specific knowledge, and
- broad, generalist awareness of how complex systems interoperate.

The job market is over-saturated with basic Python and data science knowledge. There is need for deeper skills deeper in the stack and more flexible conceptual knowledge across the stack.
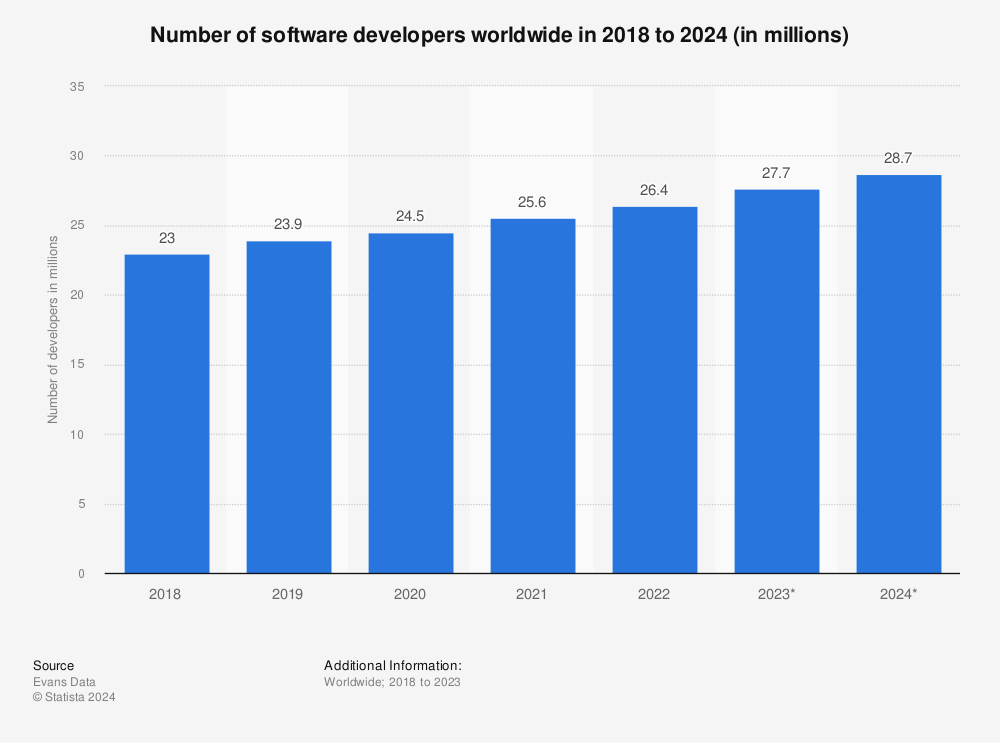
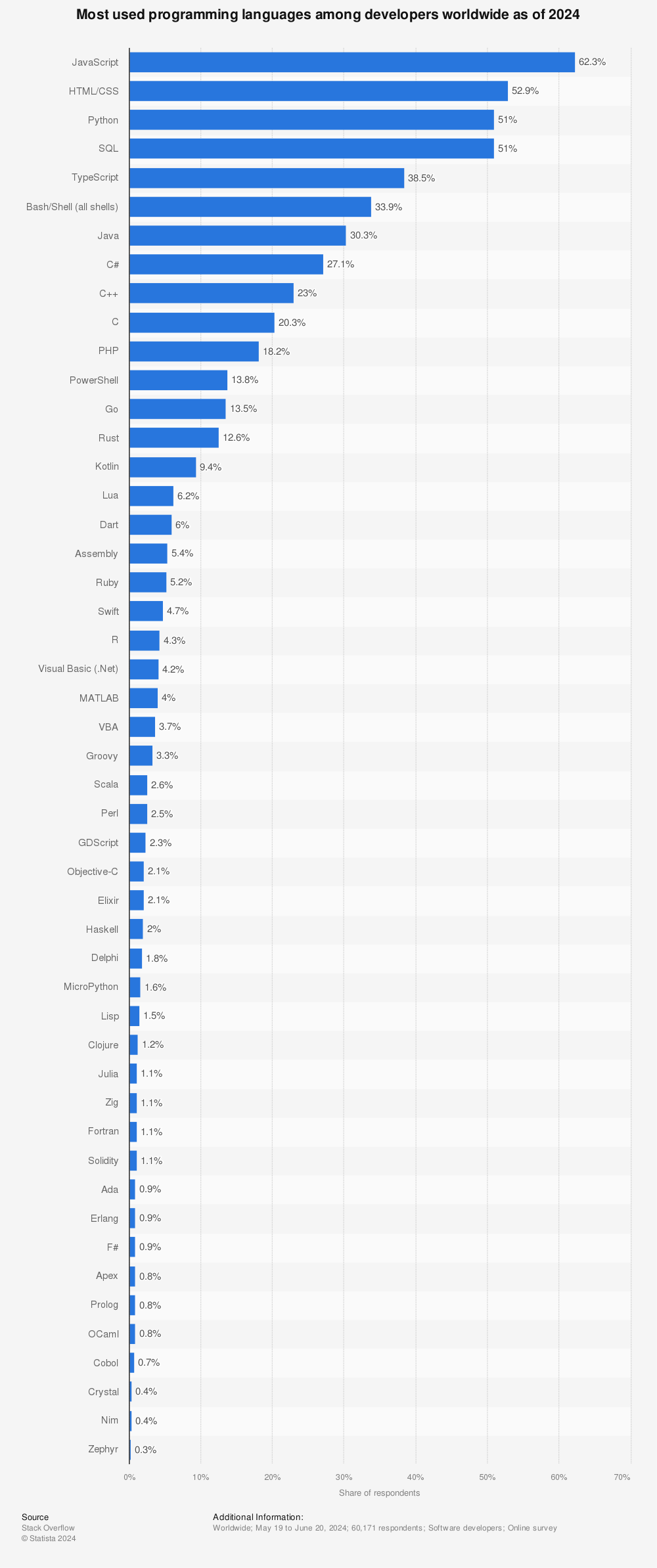
Intro to PyTorch: A motivating example
Deep learning boomed in 2012, driving the resurgence of interest and current AI hype wave. It requires massive computation, in the fastest possible programming languages. Native Python code is wayyy to slow for this, but is a convenient interface for writing AI programs due to its readability and ease of use. So we wrap lower-level languages with Python.
Whereever you go, there you are.
Whereever you try to make AI in the 2020s, there Python is.

Let’s start with a deep learning 101 example and use it to wade into how C/C++ interacts with a deep learning program written in Python. Run the code here by repeatedly doing shift+enter if you are unfamiliar with deep learning or running Python code.
Then come back here.
The code is written in Python so needs to be executed by a Python interpreter.
To understand how this example interacts with lower-level languages, the next section starts by examining how Python generally interfaces with C.
Level 1: Understanding lower levels makes for better, more efficient use of higher-level abstractions
Let’s get some key facts that apply to the vast majority of Python codes laid out.
- Python is C.
- All data in Python is represented as a
PyObject, C structs allocated on the heap. - The Python interpreter is the
main.cprogram of CPython.
What does it mean for an interpreted language to be written in a compiled language?
When a developer or CI system runs a command like this in their terminal:
Running a Python program through the interpreter.
Opening an application from the command line.
Where does this executable program come from?
How is Python built?
How does it execute a Python program (another set of files with .py extension)?
The build process
Python is software, and like any mature software has different versions. There are various programs that manage versions of Python installations on your laptop or virtual machines.
apt- Advanced Package Tool, the default package manager for Debian-based Linux distributions (like Ubuntu). It can install Python from system repositories, but typically provides older, stable versions that may lag behind the latest Python releases.venv- Python’s built-in module for creating lightweight virtual environments. It doesn’t manage Python versions itself, but creates isolated environments using your system’s installed Python version to avoid package conflicts between projects.conda- A cross-platform package manager and environment manager that can install Python itself along with packages from multiple languages (Python, R, C++, etc.). Popular in data science due to its ability to handle complex dependencies and binary packages.poetry- A modern dependency management and packaging tool that handles virtual environments, dependency resolution, and package publishing. It usespyproject.tomlfor configuration and focuses on reproducible builds.uv- A fast Python package installer and resolver written in Rust, designed as a drop-in replacement forpipandpip-tools. It can also manage Python versions and virtual environments with significantly faster performance. It manages a.venvinside your repo, driven by apyproject.tomlfile.
These systems know how to fetch already built versions of Python over the internet.
Ok, but what if you want to build Python from scratch?
Building Python from source
To build Python from source code, you can follow these steps:
Download the source code:
terminal
Download and extract Python source code from python.org or GitHub.Install build dependencies (on Ubuntu/Debian):
terminal
Install necessary build dependencies for compiling Python from source.Configure and build:
terminal
Configure and compile Python with optimizations.Verify the installation:
terminal
Check that the newly built Python version is working correctly.
How does the terminal find Python?
When you type python /path/to/program_entrypoint.py in your terminal, the shell uses the PATH environment variable to locate the python executable:
PATH resolution: The shell searches through directories listed in your
PATHenvironment variable (in order) until it finds an executable namedpython.Check your PATH:
terminal
View your PATH environment variable to see where the shell searches for executables.Find where Python is installed:
terminal
Locate the Python executable and check if it is a symlink.Common Python locations:
- System installations:
/usr/bin/python3,/usr/local/bin/python3 - Conda environments:
~/miniconda3/envs/myenv/bin/python - Virtual environments:
./venv/bin/python
- System installations:
Virtual environment activation modifies your PATH:
terminal
How virtual environment activation changes your PATH to use the environment Python.
The shell executes the first python executable it finds in the PATH, which is why virtual environment activation works by prepending the environment’s bin directory to your PATH.
Now that we know how to fetch or build Python so it exists as an executable, what happens when a program is run?
The interpretation process
Source Code: A Python program starts as source code, text files (usually in
.pyfiles) containing the program’s logic.Lexical Analysis: The first step in interpreting source code is lexical analysis, where the interpreter (a compiled C program) breaks down the content in the files into a series of tokens. The tokens are the basic building blocks of the Python programming language, such as keywords, identifiers, literals, and symbols.
For example, the line
x = 42 + ywould be tokenized as:x(identifier)=(assignment operator)42(integer literal)+(addition operator)y(identifier)
Syntax Analysis: After tokenization, the interpreter performs syntax analysis, also known as parsing. This checks if the tokens form valid statements according to the language’s grammar rules.
For example,
x = 42 +would fail syntax analysis because the expression is incomplete - the+operator expects another operand. The parser knows from Python’s grammar rules that this is invalid syntax.Semantic Analysis: Finally, the interpreter performs semantic analysis, checking the meaning of the program and ensuring that it adheres to the language’s semantics.
For example, even if
x = y + zpasses syntax analysis, semantic analysis might detect thatyis used before being defined, raising aNameErrorat runtime when the interpreter tries to resolve the variable.
After this, the program is ready to execute line-by-line.
Managing dependencies
Python programs, especially in data science and AI, often spend the first few lines of a file importing other packages for reuse and modularity.
Common import patterns in Python programs showing built-in and third-party modules.
- Where do imported packages come from?
- How does this impact the way we write, build, and run Python programs?
- What should Python developers be aware of?
Python dependencies, package managers, and C
When you run Python code, you’re likely using a virtual environment with various dependencies installed. These dependencies often include packages written in C, Fortran, or Rust, which provide optimized performance for tasks like large-scale numerical computations.
Widely used packages like torch and numpy, for example, use Python interfaces
bound to C code to achieve high performance - the proof is in the pudding. Modern Python tooling increasingly leverages Rust to gain performance in a similar way. Notable examples include:
ruff- An extremely fast Python linter and code formatter written in Rust, replacing tools likeflake8andblackwith orders of magnitude speed improvements.polars- A fast DataFrame library that provides a Python interface to Rust-based data processing, causing many to migrate from thepandasmodule, a workhorse in data analytics.pydantic- Uses a Rust core (pydantic-core) for data validation and serialization, dramatically improving performance over pure Python implementations.uv- A Rust-based Python package installer we mentioned earlier, providing pip-compatible functionality with significant speed improvements.
By understanding how our Python code interacts with these lower-level systems languages, we can better appreciate the complexity and power of modern programming languages, package our code better, and make customizations if necessary.
What happens when you install packages to reuse in your program?
Earlier we saw how Python itself is typically installed using a dependency management solution like conda, or increasingly uv.
When installing packages with C code, such as PyTorch, the process involves either using pre-built “wheels” or building from a source distribution. Read more.
The pre-built packages are stored in package repositories. The most common one that all Python devs discover is PyPi, which is public infrastructure where developers distribute builds of their packages and where you fetch those packages from by default when running:
Generic pip install command showing how packages are fetched from PyPI.
The PyTorch team builds the package for many operating systems, hardware, and Python version combinations, and does this for you so that when you run:
A request sent from your computer to be routed to wherever on the internet the generous PyTorch team distributes versions of the codebase to the masses.
the pip program retrieves a pre-built package that is optimized for your system, eliminating the need for dynamic compilation from source.
The resulting package includes compiled C code in the form of shared libraries, which are loaded by the Python interpreter to provide significant speedups in AI software.
Now, let’s shift our focus to what happens when we run the Python interpreter. This process initiates a series of steps that enable the execution of Python code.
A seamless abstraction: lower-level optimization with higher-level efficiency
The output of semantic analysis is an abstract syntax tree (AST). The AST is converted into bytecode that the interpreter program can execute. As execution occurs, shared libraries containing compiled C code are loaded. All of this happens without Python developers needing to care, and we can write programs like this example of how PyTorch uses C code to provide optimized performance:
Simple example showing how PyTorch uses compiled C code for tensor operations.
What overhead is Python introducing?
While Python provides an elegant high-level interface, it comes with performance costs compared to compiled languages:
Interpretation overhead: Every line of Python code must be interpreted at runtime, unlike compiled languages where the translation to machine code happens once during compilation. This creates a constant performance tax on execution.
Example showing how Python interpretation overhead affects performance in loops.
Dynamic typing: Python’s flexibility in allowing variables to change types (x = 5; x = "hello") requires runtime type checking and prevents many compiler optimizations that statically-typed languages benefit from.
Example demonstrating Python dynamic typing overhead with runtime type checking.
Object overhead: Everything in Python is a PyObject with associated metadata. Even a simple integer like 42 carries significantly more memory overhead than a raw 32-bit integer in C.
Comparing Python object size overhead versus raw C types.
Global Interpreter Lock (GIL): Python’s GIL prevents true multithreading for CPU-bound tasks, forcing developers to use multiprocessing for parallelism, which introduces additional overhead.
Example showing how the GIL prevents parallel execution of CPU-bound threads.
However, this overhead becomes negligible when most computation happens in optimized C/Rust libraries. Libraries like NumPy and PyTorch are designed to:
- Minimize time spent in Python interpreter
- Batch operations to amortize the cost of crossing the Python/C boundary
- Release the GIL during computation-heavy operations
This is why a NumPy array operation can be nearly as fast as pure C, despite being called from Python - the actual work happens in compiled code, with Python serving primarily as a coordination layer.
Level 2: Customizing the lower-levels
Python is a high-level language, but as the previous section demonstrated, Python code often calls interfaces to code implemented in other languages. In this section, we’ll look at Python and the two most common integration languages in 2025, the old standard C/C++ and the new kid on the block Rust.
C/C++
There are several approaches to integrating C/C++ with Python, each with different trade-offs:
1. ctypes - Call existing C libraries
Use case: You have an existing C library and want to call it from Python without modifying it.
2. Python C API - Write native Python extensions
Use case: Maximum performance with direct integration into Python’s object system.
3. Pybind11 - Modern C++ integration
Use case: Modern C++ with automatic type conversions and clean syntax.
Rust
Rust has emerged as an excellent choice for Python extensions due to its memory safety, performance, and excellent tooling. The Rust ecosystem provides several ways to integrate with Python:
1. PyO3 - The standard Rust-Python bridge
PyO3 is the most popular crate for creating Python extensions in Rust, providing a safe and ergonomic API.
2. Maturin - Build tool for Python-Rust projects
Maturin simplifies building and distributing Rust-based Python extensions:
Maturin commands for building and distributing Rust-Python extensions.
3. Real-world example: Performance comparison
Here’s a practical example showing Rust’s performance benefits:
Benchmark comparing Python vs Rust performance for Fibonacci calculation.
Why choose C/C++ over Rust?
Despite Rust’s advantages, there are still compelling reasons to choose C/C++ for Python extensions:
Existing ecosystem and libraries: Many critical libraries only exist in C/C++. If you need to integrate with BLAS, LAPACK, OpenCV, or domain-specific C libraries, wrapping existing C/C++ code is often more practical than rewriting in Rust.
Example of wrapping existing optimized C libraries like Intel MKL.
Team expertise: C/C++ has a much larger developer pool. If your team already knows C/C++ well, the productivity gains from familiar tooling and debugging workflows often outweigh Rust’s safety benefits.
Mature tooling and debugging: C/C++ has decades of tooling development:
- Profilers: Intel VTune, Perf, Valgrind work seamlessly with C/C++
- Debuggers: GDB integration is rock-solid
- Build systems: CMake, Autotools, and existing CI/CD pipelines
Performance edge cases: While Rust is generally as fast as C++, certain scenarios might favor C/C++:
- Zero-cost abstractions sometimes have subtle costs in Rust
- Manual memory management can be more optimal for specific use cases
- Some compiler optimizations are more mature in GCC/Clang
Binary size: C/C++ can produce smaller binaries, which matters for:
- Embedded systems integration
- Docker images where every MB counts
- Mobile applications with size constraints
Industry standards: Some domains are deeply entrenched in C/C++:
- High-frequency trading systems
- Real-time control systems
- Legacy scientific computing codebases
Lower learning curve: C syntax is simpler to learn initially, even if it’s more dangerous. For quick prototypes or one-off extensions, C might be faster to implement.
The choice ultimately depends on your specific constraints: team skills, existing codebase, performance requirements, and maintenance timeline. Both languages have their place in the Python ecosystem.
CUDA
For computationally intensive tasks, especially in AI and scientific computing, Graphics Processing Units (GPUs) offer massive parallelization potential. CUDA (Compute Unified Device Architecture) provides a framework for GPU programming, and Python offers several excellent libraries for CUDA integration.
Why CUDA matters for Python developers
Modern AI workloads are increasingly GPU-bound. While CPython’s GIL prevents effective CPU parallelization, GPUs can execute thousands of threads simultaneously. Understanding CUDA integration helps you:
- Scale beyond CPU limits: Neural network training, image processing, and numerical simulations benefit enormously from GPU acceleration
- Optimize existing workflows: Many data science pipelines can be accelerated 10-100x by moving bottlenecks to GPU
- Build competitive AI applications: GPU optimization is often the difference between research prototypes and production systems
Quick wins: Existing GPU libraries
Most Python developers can get significant GPU acceleration using existing libraries without writing custom CUDA code:
Quick GPU acceleration using existing Python libraries like CuPy and Numba.
These libraries handle the Python-CUDA interface complexity for you, but understanding what happens under the hood helps with performance optimization and debugging.
Building custom CUDA extensions: The full interoperability stack
For maximum performance and control, you can build custom CUDA extensions that directly interface with Python. This involves understanding the complete interoperability stack:
The CUDA kernel layer:
Raw CUDA kernels showing GPU parallelization and memory management patterns.
The C++ interface layer:
C++ wrapper managing Python-CUDA memory transfers and kernel launches.
Build configuration:
Build system configuration for compiling CUDA extensions with Python.
Python usage and performance analysis:
Key interoperability considerations
Memory layout compatibility: Python NumPy arrays must be C-contiguous for efficient GPU transfer. The CUDA runtime expects specific memory alignment that may differ from Python’s default object layout.
Data type mapping: Python’s dynamic typing requires explicit mapping to CUDA’s static types. numpy.float32 maps to CUDA float, but numpy.float64 requires different kernel implementations.
Reference counting and lifetime: GPU memory isn’t subject to Python’s garbage collector. Manual memory management through RAII patterns (like the CudaBuffer class above) prevents memory leaks.
Asynchronous execution: CUDA operations are asynchronous by default, but Python expects synchronous semantics. Proper stream management and synchronization points are critical for correctness.
Error handling: CUDA errors don’t automatically propagate to Python exceptions. Custom error checking (like the CUDA_CHECK macro) ensures Python code can handle GPU failures gracefully.
When to build custom CUDA extensions
Build custom extensions when:
- Existing libraries don’t support your specific algorithm
- You need fine-grained control over GPU memory management
- Performance bottlenecks require kernel-level optimization
- You’re implementing novel GPU algorithms for research/production
Stick with existing libraries when:
- Standard operations (linear algebra, convolutions) meet your needs
- Development time constraints outweigh performance gains
- Team lacks CUDA/C++ expertise for maintenance
The custom CUDA extension approach represents the deepest level of Python-systems integration: managing memory across language boundaries, handling asynchronous execution models, and bridging Python’s dynamic semantics with GPU hardware constraints.
What can you do with these skills?
Understanding Python’s interoperability with systems languages opens several career and technical opportunities:
Immediate applications
Performance optimization: When your Python code hits performance bottlenecks, you can now identify which operations would benefit from C/Rust implementations and implement them effectively.
Library integration: Many powerful libraries (computer vision, signal processing, scientific computing) are written in C/C++. Understanding the integration patterns helps you leverage existing optimized code rather than reinventing wheels.
Custom extensions: Build domain-specific optimizations for your applications. Data processing pipelines, mathematical computations, and real-time systems often need this hybrid approach.
Career differentiation
Systems thinking: While many developers work purely in high-level languages, understanding the full stack makes you more effective at:
- Debugging performance issues
- Making architectural decisions
- Leading technical discussions about trade-offs
AI/ML infrastructure: As AI systems scale, the bottlenecks often appear at the intersection of Python convenience and systems performance. Companies need engineers who can work across this boundary.
Open source contributions: Many important Python libraries need contributors who understand both the Python interface and the underlying implementation. This knowledge lets you contribute meaningfully to projects like PyTorch, NumPy, or emerging Rust-based tools.
Next steps to build these skills
Start small: Pick a computationally expensive function in your current Python projects and reimplement it in C or Rust. Measure the performance difference and integration complexity.
Contribute to existing projects: Find Python libraries that use C/Rust extensions and examine their build systems, interface design, and testing approaches. Submit small improvements or documentation fixes.
Build a mixed-language project: Create a Python application that delegates specific tasks to lower-level implementations. This gives you hands-on experience with the full development lifecycle.
Study production systems: Examine how companies like Instagram, Dropbox, or Netflix handle Python at scale. Many publish engineering blogs detailing their approaches to performance optimization.
The key insight is that modern software development increasingly rewards generalists who can work across abstraction levels, not just specialists in single languages. Understanding these integration patterns positions you to solve problems that pure high-level or low-level developers cannot address alone.
More resources
- Interfacting with C by Valentin Haenel